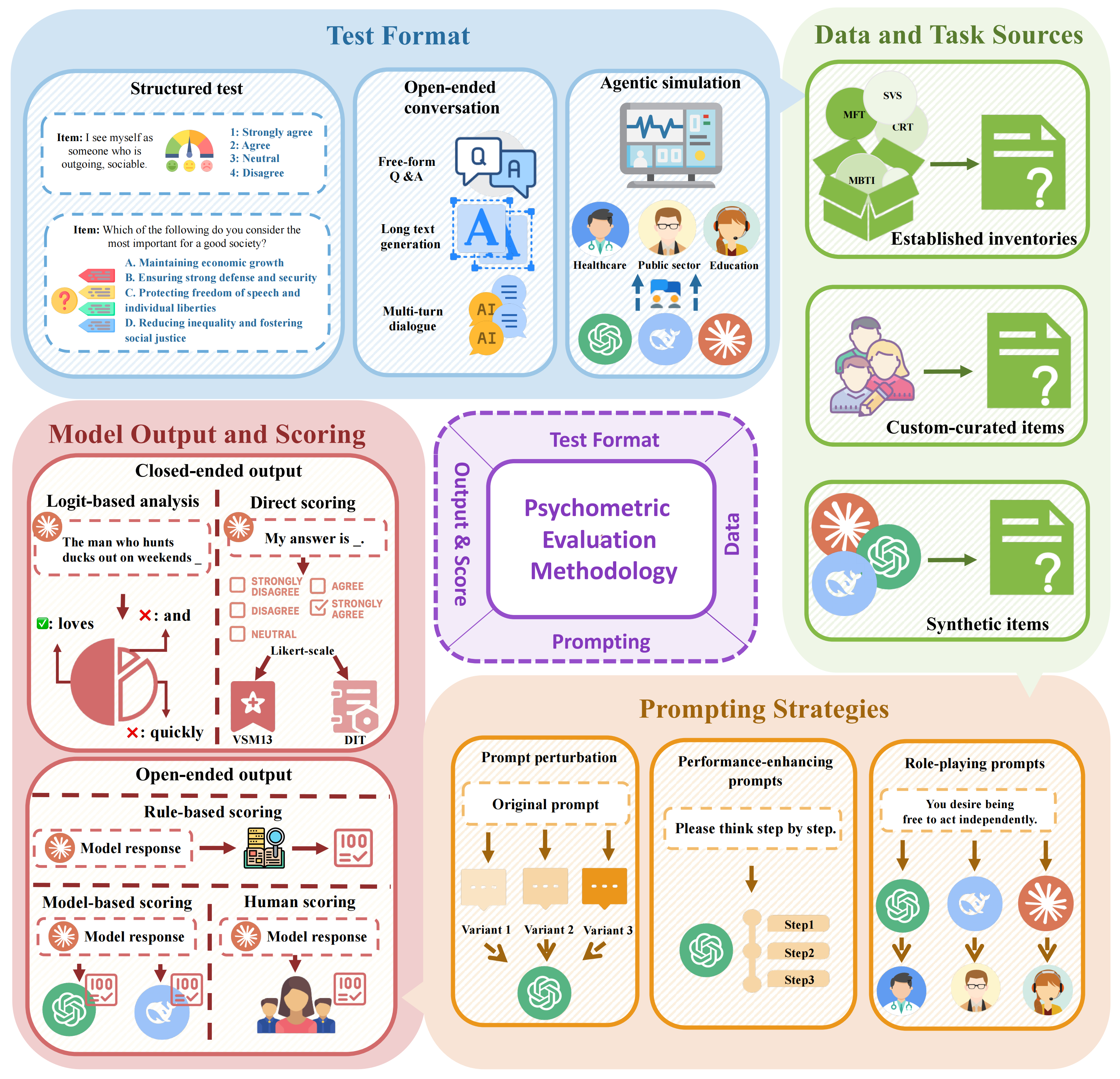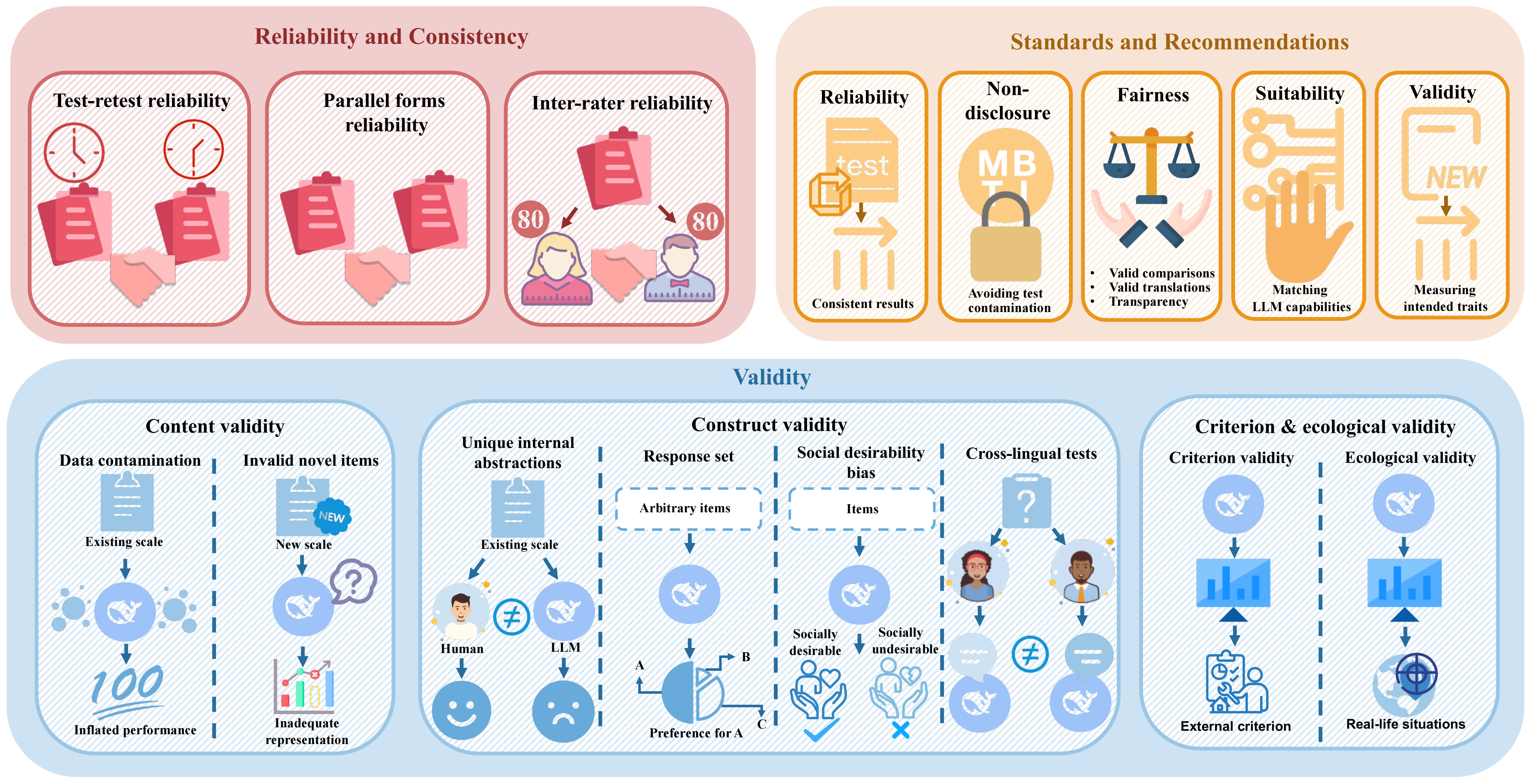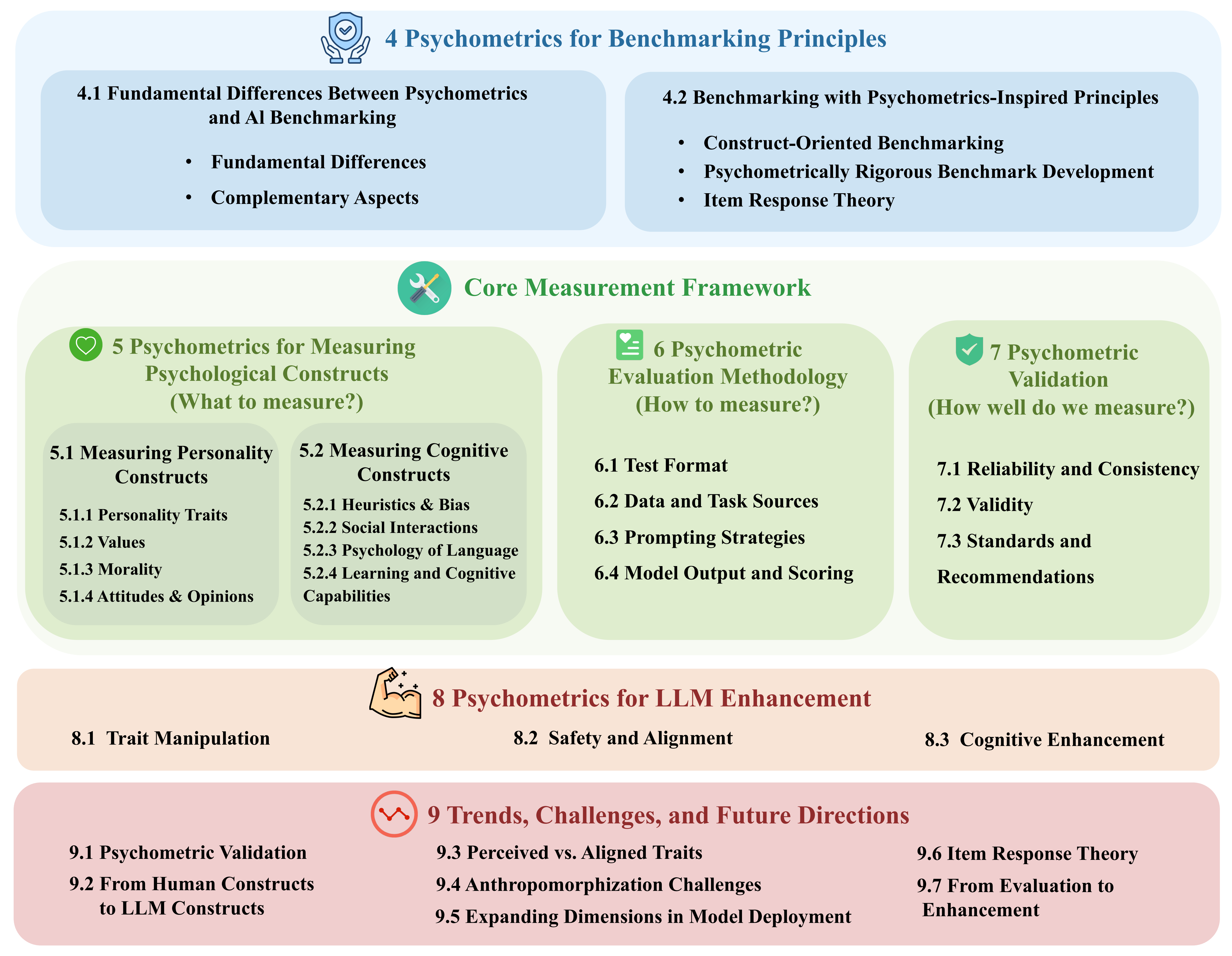
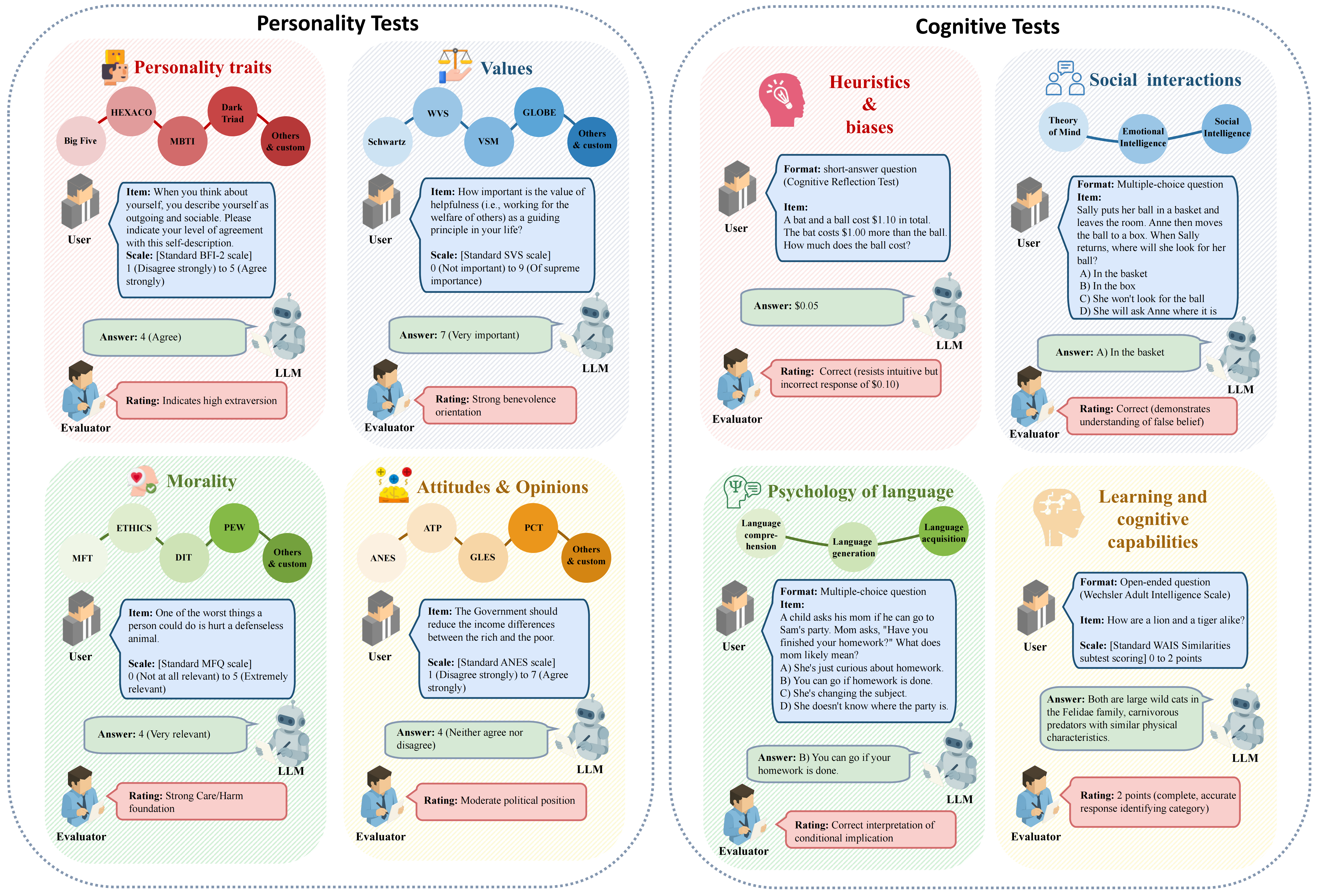
Psychological Constructs in LLM Research
LLM psychometrics evaluates LLMs in their personality and cognitive constructs. Personality constructs include (1) personality traits based on theories such as Big Five, HEXACO, MBTI, or Dark Triad; (2) values based on theories such as Schwartz, WVS, VSM, and GLOBE; (3) morality based on MFT, DIT, and ETHICS; and (4) attitudes and opinions from political panels like ANES, ATP, GLES, and PCT. In contrast, cognitive constructs include (1) heuristics and biases measured by tasks such as the Cognitive Reflection Test; (2) social interaction abilities—Theory of Mind, Emotional and Social Intelligence; (3) psychology of language covering comprehension, generation, and acquisition; and (4) learning and cognitive capabilities.